
【游戏设计】UE5的Nanite实现浅析/虚拟多边形技术原理
虚幻引擎5(UE5)一公布就火爆全球,其中两大核心技术纷纷迎来了很多行业工作者的研究与探讨,下面结合一些信息为大家介绍UE5中的两大核心技术:Nanite与Lumen。
相信大家都知道了Nanite是多边形虚拟化的技术,现在先来讲一下什么是虚拟化吧!
一个虚拟场景是由很多模型构成的,而这些模型的基础是三角形,所以三角形的数量通常都非常的多。这造成了一个问题:由于三角形的数量非常多,但是我们所能看到的三角形数量非常的少。这使得我们需要把很多不必要的三角形剔除,增加渲染的效率并节省时间。

所以后来出现了细节级别(LOD)的概念,对于远处物体使用粗糙的版本,近的物体使用高精度的版本。但这些还只停留在模型级别,不能针对于更大规模的三角形构成或者大规模的影视游戏场景。
而Nanite技术可以虚拟化几何体,Nanite能极快的渲染超多的三角面,并且能够将很多的三角面无损压缩成很少。Nanite能够展示像素级别的细节,这使得几何体中的三角形也常是像素大小的,这个级别的几何体细节也要求阴影能够精确到像素。

有了这个大家就不必考虑几何体的数量,绘制调用次数,或者占用内存。我们可以使用各种资源(甚至是由数以亿计的多边形组成的影视级作品)直接导入到UE5中,并且不用为了满足帧率而浪费时间去优化资源,也无需再考虑多边形数量预算、多边形内存预算或绘制次数预算等。并且不用将细节烘焙到法线贴图或创建与编辑LOD。
使用Nanite可以直接使用这些模型,导入的模型作品的画面质量不会降低。也可以在Megascans库里找到资源进行运用。
众所周知,现代GPU有两条流水线,一条处理三角形网格,一条处理纹理图像。
相比于图像,三角形网格的组合结构是不规则的,因此无法直接用硬件表达和随机存取,需要复杂的算法来动态构建。
Nanite的方法:
几何图像:就是直接对网格结构进行曲面参数化,即RGB表示顶点位置,像素排列表示顶点组成三角形的关系,生成几何图像。
虚拟纹理技术:将所有的纹理融合成一张巨大的纹理图像,覆盖整个游戏世界,用四叉树管理每一个分割成同样大小的page,动态加载当前渲染场景所需要的page。
Nanite构建过程
Nanite的构建过程采用多线程加速,从代码看来,似乎UE5的Task Queue也做过一些重构,所以其线程组织代码比UE4略好。
把模型分成Cluster,类似Meshader中的Meshlet。划分在拓扑空间中邻近的Cluster,是为了提高访问数据时Cache命中率。Cluster分割使用Metis1库。在UE5中Metis以库的形式存在,有兴趣的同学可以去官网上扒扒源码。

生成分层的Cluster mips和ClusterGroup mips,类似于传统模型Lod,或者纹理的Mipmap层级。
上层的Cluster对下层Cluster进行合并和简化,简化模型使用的依旧是MeshSimpler,使用的是经典的Quadric Error Metrics2算法,并没有使用UE4.2x之后所加入的体素化的做法,尚不知是何原因。不同的Cluster分层示意如下:
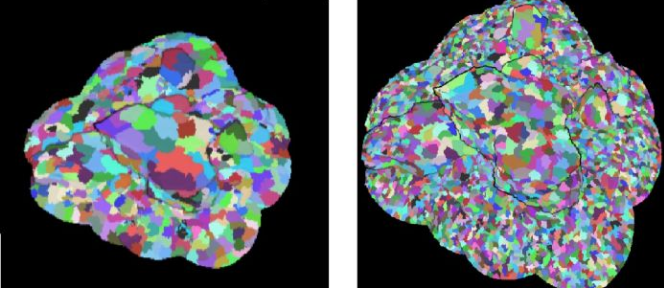
分层的Cluster结构有许多的好处,其中之一就是渲染时可以根据和在屏幕上的投影大小来确定使用哪一层级的Cluster来渲染,可以简单的理解为把模型的Lod层级切换粒度由整个模型做到了Cluster级。上图所示的石块有1.6万个最高质量的Cluster,在数值上可见其粒度相对模型来说有多大的改观。
针对相邻Cluster分属不同的层级,其邻接边会产生接缝的问题,Nanite的处理方式是在简化时Lock Edges3,这也是在UE4.2x中的既有功能。

压缩模型的顶点属性、索引和材质数据,因为Cluster体积很小且单位体积中的三角形数量非常高,故其如果不做压缩,其存储空间、IO效率、渲染传输带宽在目前的硬件条件下几乎没有达到实时渲染的可能性————一个百万面的模型光Mesh的顶点和索引数据就有140MB,上亿三角形得有多大的数据量是显而易见的,而这还只是一屏的数据量。所以Nanite的数据是高度压缩的数据。
1.对模型顶点属性如Position,TextureCoordinates,normal按Cluster做量化4(有损),其中法线使用OctahedronEncode。在渲染程序里做量化的常用方法是先求到数据集的[min,max]区间,然后把数据集按max-min缩放到0~1之间进行存储和使用。这种量化的方式的局限性在于顶点在空间中的分布不是均匀分布的,所以其精度很难得到有效的利用(比如把顶点压缩成float16)。

但对于Nanite来说,这个问题却并不大,因为单个Cluster三角形在空间上分布是非常密集的。同时因为Cluster的数据集中程度高,它可以使用更少的位数来存储顶点属性。事实上Cluster量化时不是使用一个分量对应一个float16或uint8,而是使用可变位流(有点类似Google ProtoBuffer的整数压缩)来进行压缩——即它一个分量可能只占4bit。
2. Mesh Index做Strip,因为单个Cluster并没有多少三角形,其单个Index大小也大都占不满16bit。

构建Cull用的BVH树,上面提到的Cluster分层结构仅用于处理Lod切换,而Nanite BVH则用于剔除。空间中常用的BVH为Octree或kd-tree,这儿所谓的轴向树其分割方式类似于Kd-tree,是一次性对在Boundbox的最长轴上进行划分,不同的是kd-tree划出两个子节点,而Nanite的BVH Tree则一次最多划分出8个子节点。
为Cluster/Cluster Group建立Page结构用于存储模型数据。Nanite使用的Page结构大小为128KB。它会优先把空间邻近且处于同一mip层级的ClusterGroup放在同一个Page表中。为保证空间邻近性,其排序使用的是Morton3D5曲线。如下图所示

最后把Page数据存盘,这儿可选的,可以使用Lz4进行数据的无损压缩,最后完成Nanite的构建。
Nanite渲染过程
Nanite的渲染是糅合在UE4的传统渲染过程中的,它要解决的核心问题是,如何输出g-buffer的相关数据,因为有了无差别的g-buffer数据后,光照计算及后处理理论上就可以和几何表达形式上无关了。
Primtive数据
Nanite资源的Primitive数据都使用StructureBuffer存在于GPU Memory中,这就为后续的剔除、合批等操作提供了GPU Driven式的便利。
Cull
Nanite的Cull在是GPU Driven的,在CS中执行的,它分为两大块: 一是Primitive Instance级,为每个模型执行FrustumCull/HZB Cull 二是内部BVH树及Cluster级,分层的为BVH进行剔除,在一直相交的情形下会下降到Cluster Boundary,注意到目前的Nanite Cluster剔除并没有剔除面积很小的三角形,也没有做背面剔除。 Cull的同时它还会做一件事:标记该三角形走软件光栅化还是走硬件光栅化——只有面积小于给定值的三角形才会走软件光栅化
光栅化(Rasterization)
Nanite 的光栅化是混合的光栅化方案:对于小三角形来说,它使用的是基于CS的软件光栅化;对于大三角形来说,它使用的是基于传统的硬件光栅化 Nanite对于光栅化的性能优化包括:
压缩的数据具有更小的输入内存带宽使用率 对于一个准像素级的三角形光栅化来说,硬件总是会一次性光栅化四个,会有倍于软光栅的开销 * Nanite的软光栅输出数据为VisibilityBuffer6(仅包含InstanceID,TriangleID,Depth),具有更小的输出带宽使用率 其中1,3是软硬件光栅化都实现的优化,2则仅限于小三角形的软光栅
如果硬件支持Async Computer Shader,Nanite的硬件光栅化和基于CS的软光栅是会重叠执行的,这将进一步优化光栅化的整体执行时长
重建Material Attribute及执行光照
使用VisibilityBuffer重建出光照所需的材质属性,然后使用和传统Deferred Shading相同的PS进行光照计算。后续的UI及后处理渲染就完全和Nanite解耦了。
转载声明:本文来源于网络,不作任何商业用途。
全部评论


暂无留言,赶紧抢占沙发
热门资讯

成长贴 | 之前觉得很困难的漫画创作,我6个月就学会了...

【绘画教程】教你如何画交叉抱胸的姿势!

你知道日本武士刀的构造与画法吗?

3Dmax关闭时无响应、无法退出该怎么办?
ZBrush合并/分开模型的方法

新加坡插画师Sean Raiko Tay作品(二)

剪映和pr有什么区别?

成长帖∣兴趣跟职业,我两个都要了!!biu~...
ZBrush中常用笔刷工具和使用方法!





